
こん○○は、よふかしわーくすのよふかしさんです
今回は、音声の文字起こしに関する実践的な技術検証をまとめてみました
会議、講演、電話など、なんらかの音声での記録を文字に起こしたいってことがあるかと思います
録音された会議やインタビューを手動で文字起こしするのは、時間も集中力も膨大に奪われますよね…
再生→停止→入力…このループは音声時間の2~3倍の工数がかかることもあります…
そんな手間を排除しつつ、秘匿や個人情報的にも問題のない方法ってないかなぁと探して試してみました
音声データの文字起こし、自動化する方法とは?
音声データを効率よく文字起こしするには、どうすれば自動化できるのでしょうか?
OpenAIが提供する「Whisper」モデルは、高精度な音声認識を可能にする革新的なモデルです
今回はこのWhisperを活用し、Python + CUDA(NVIDIA製GPU) を組み合わせたローカル環境で、音声の高速かつ高精度な文字起こしシステムを構築してみました
本記事では、初期設定から実行方法まで、ステップごとにわかりやすく解説していきます
音声文字起こしサービス比較(無料枠が充実したおすすめ6選)
巷にはAI等を活用した様々なサービスがありますが、当然有料なわけでして
無料枠はあくまでトライアルの位置づけなので、色々と制約があるわけです
ざっと、整理してみたのが下記です
🔹 TurboScribe
- URL: https://turboscribe.ai
- 無料枠:1日3ファイル × 各30分まで
- 備考:Whisperベースの高精度。動画形式にも対応。クレジットカード不要で登録可能。
🔹 toruno(トルノ)
- URL: https://toruno.biz
- 無料枠:パーソナルプランで累計3時間まで
- 備考:Windows専用アプリ。音声+画面+テキストの同時記録に強みあり。iPhone版アプリも提供。
🔹 Otter.ai
- URL: https://otter.ai
- 無料枠:月600分まで(1会話あたり最大30分)
- 備考:英語中心だが日本語も認識可能。Web&iOS対応。チーム共有機能付き。
🔹 Descript
- URL: https://www.descript.com
- 無料枠:初期で3時間まで利用可能
- 備考:音声と映像の統合編集に対応。無料枠を超えると「読み取り専用」になる点に注意。
🔹 Rimo Voice
- URL: https://voice-rimo.com
- 無料枠:1ファイル最大60分まで(利用回数無制限)
- 備考:SNSログインで利用可。話者分離や高度な編集機能を搭載。日本語にも強い。
🔹 CLOVA Note
- URL: https://clovanote.line.me
- 無料枠:毎月300分(+同意で追加300分)=最大600分/月。スマホアプリ版は無制限
- 備考:LINE連携で利用可能。会議や講義録に特化。話者分離・検索・キーワード抽出も対応。
但し、サービス向上のためにユーザーデータの提供が必須だったりもするので
どうしても秘匿や個人情報に関しては気になる部分が残ります…
どうでもいい音声データで試してみたところ、
- Turbo Scribe
- なかなか精度よい
- toruno
- 結構精度悪い
という感じで、サービスによっての精度もマチマチな模様
なので、有料課金するにしても、事前にしっかりトライアルするのは重要そうです
Whisperとは?高精度な音声認識AIの概要
WhisperはOpenAIが公開した音声認識モデルでして、主な特徴は以下の通りです
- 高い精度:背景雑音やアクセントにも強い
- 多言語対応:日本語含む98言語に対応
- 発話区切りや話者識別(スピーカー分離)も可能
- オープンソースかつローカルで完結できる
つまり、無料で文字起こし環境をローカルで構築可能、というのが素晴らしいです
あとは、環境の構築とプログラムのコーディングだけ、です
今回はPythonでやってみたいと思います
WhisperとCUDA環境に最適なPython・PyTorchバージョンは?
色々調べた結果、2025年7月現在で最新と思われる下記バージョンで環境構築しています
| ツール名 | インストールバージョン例 | バージョン選定の背景・理由 |
|---|---|---|
| PyTorch | 2.7.1+cu128 | Stableの最新Ver |
| CUDA Toolkit | 12.8 | PyTorch対応の最新Ver |
| Python | 3.12.10 | PyTorch対応の最新Ver |
| その他のライブラリ | 最新 | 特に制約なし |
ググってみつかる記事ですと、
PyTorch依存でCUDAは11.8で、Pythonも3.11系を使っている場合が多かったです
今回は人柱的要素も含めて色々試した結果、恐らく現時点で使用可能な最新になっています
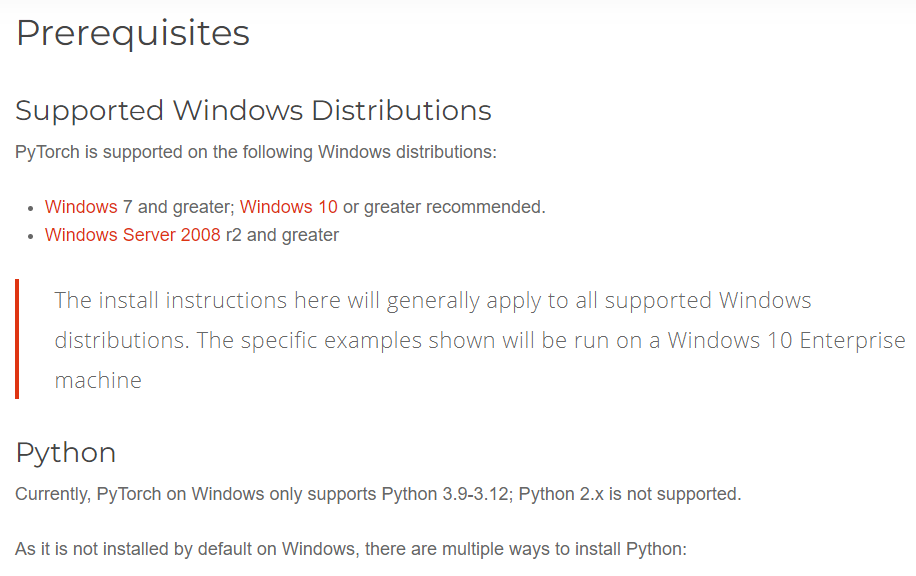
Pythonは3.13系に上げるとどこかでエラーが起きるのでダメです
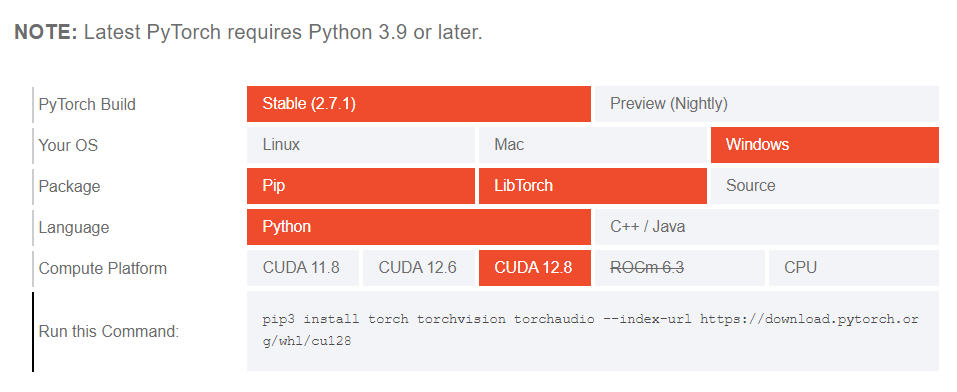
参考までにPyTorchのサイトのスクショを貼っておきます

ここを見ると、CUDAの対応バージョンがわかる
この辺りにOSやPythonのバージョン制約の記載がある
Pythonのインストール
Python3.12.10を入れていきます
下記URLから、所望のバージョンを見つけます
こんな感じ
今回はWindowsの64bitで進めます
Next
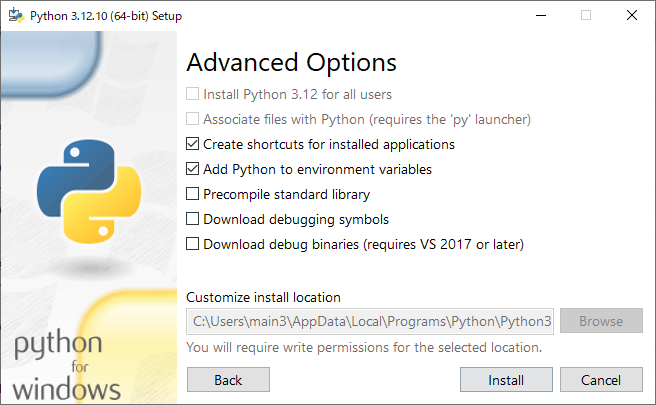
Add Python to environment variablesにチェックがついていることを確認してInstall
CUDAで書き起こし処理を高速化するメリットと導入手順
CUDAはGPUを使って文字起こしを高速化するためのツールです
GPUが搭載の場合はかなり(10倍くらい?)速くなるのでオヌヌメです
GPUが非搭載でもCPUで文字起こしできるので、その場合はこの章はSkipしてください
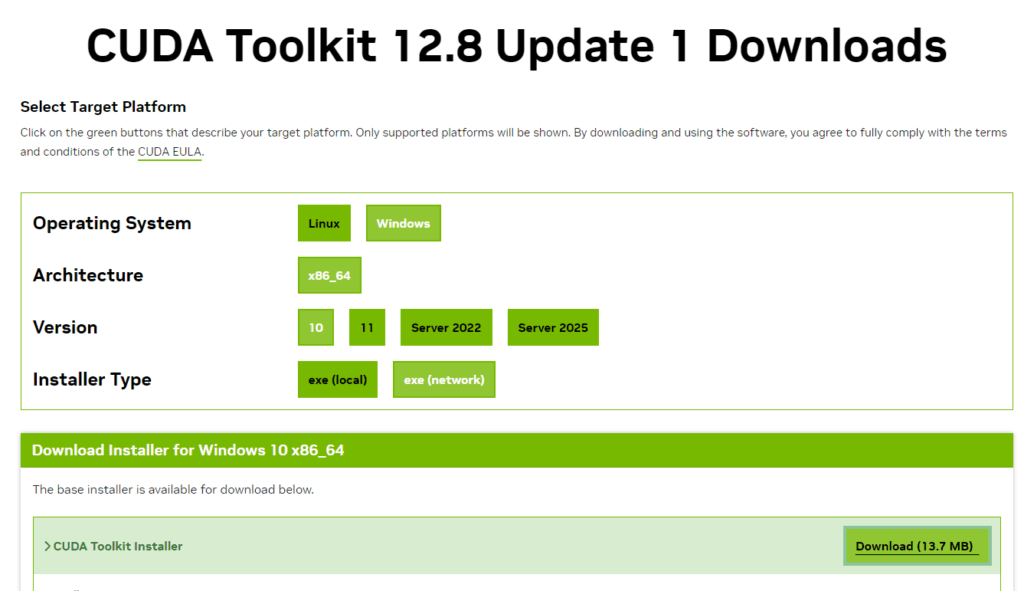
NvidiaのページからDLします

Windows、x86_64、10、exe (network)、を選択して、Download
cuda_12.8.1_windows_network.exe、がDLされるはずなので、実行
OK
同意して続行する
カスタムを選択して、次へ
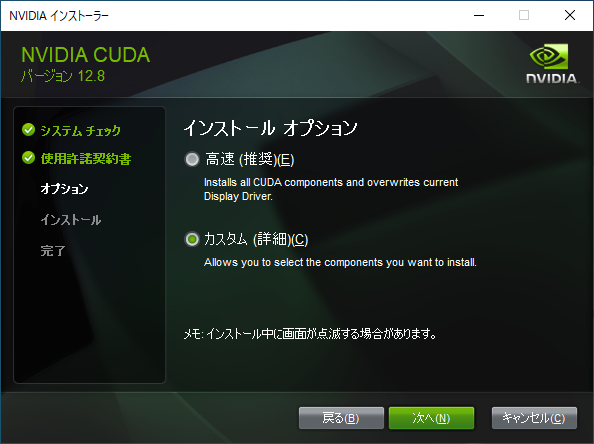
CUDAにチェックがついていることを確認
それ以外は任意です
今回はDriverも更新したかったので、チェックつけました
次へ
次へ
次へ
次へ
この後、再起動が必須です
他の作業との兼ね合いで選択してください
再起動後、インストール状況を確認します
下記コマンドを入力
nvcc --version結果が下記の様になればOK
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Fri_Feb_21_20:42:46_Pacific_Standard_Time_2025
Cuda compilation tools, release 12.8, V12.8.93
Build cuda_12.8.r12.8/compiler.35583870_0音声形式を変換するためのFFmpegのインストール
FFmpegは音声ファイルの変換に使います
最新版で問題ないです
FFmpegは公式からはソースコードしか提供されていないので、ちょっと面倒です
一番簡単なのはビルド版をGyan.devからwingetを使用してインストールする方法かなと思います
wingetはMicrosoft公式のパッケージ管理ツールなので、信頼性も高いです
下記コマンドでインストール
winget install --id=Gyan.FFmpeg -e再起動後、下記コマンドで確認します
ffmpeg -versionこんな感じになればOKです
ffmpeg version 7.1.1-full_build-www.gyan.dev Copyright (c) 2000-2025 the FFmpeg developers
built with gcc 14.2.0 (Rev1, Built by MSYS2 project)
configuration: --enable-gpl --enable-version3 --enable-static --disable-w32threads --disable-autodetect --enable-fontconfig --enable-iconv --enable-gnutls --enable-lcms2 --enable-libxml2 --enable-gmp --enable-bzlib --enable-lzma --enable-libsnappy --enable-zlib --enable-librist --enable-libsrt --enable-libssh --enable-libzmq --enable-avisynth --enable-libbluray --enable-libcaca --enable-libdvdnav --enable-libdvdread --enable-sdl2 --enable-libaribb24 --enable-libaribcaption --enable-libdav1d --enable-libdavs2 --enable-libopenjpeg --enable-libquirc --enable-libuavs3d --enable-libxevd --enable-libzvbi --enable-libqrencode --enable-librav1e --enable-libsvtav1 --enable-libvvenc --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxavs2 --enable-libxeve --enable-libxvid --enable-libaom --enable-libjxl --enable-libvpx --enable-mediafoundation --enable-libass --enable-frei0r --enable-libfreetype --enable-libfribidi --enable-libharfbuzz --enable-liblensfun --enable-libvidstab --enable-libvmaf --enable-libzimg --enable-amf --enable-cuda-llvm --enable-cuvid --enable-dxva2 --enable-d3d11va --enable-d3d12va --enable-ffnvcodec --enable-libvpl --enable-nvdec --enable-nvenc --enable-vaapi --enable-libshaderc --enable-vulkan --enable-libplacebo --enable-opencl --enable-libcdio --enable-libgme --enable-libmodplug --enable-libopenmpt --enable-libopencore-amrwb --enable-libmp3lame --enable-libshine --enable-libtheora --enable-libtwolame --enable-libvo-amrwbenc --enable-libcodec2 --enable-libilbc --enable-libgsm --enable-liblc3 --enable-libopencore-amrnb --enable-libopus --enable-libspeex --enable-libvorbis --enable-ladspa --enable-libbs2b --enable-libflite --enable-libmysofa --enable-librubberband --enable-libsoxr --enable-chromaprint
libavutil 59. 39.100 / 59. 39.100
libavcodec 61. 19.101 / 61. 19.101
libavformat 61. 7.100 / 61. 7.100
libavdevice 61. 3.100 / 61. 3.100
libavfilter 10. 4.100 / 10. 4.100
libswscale 8. 3.100 / 8. 3.100
libswresample 5. 3.100 / 5. 3.100
libpostproc 58. 3.100 / 58. 3.100Python仮想環境で各種ライブラリの安定動作環境を作る
よふかしさんは下記の様に、Pythonを複数バージョンインストールしているのと
各ツール開発で競合問題が起きたりもするので
今回もWhisper向けに仮想環境で構築していきます
py -0
-V:3.13 * Python 3.13 (64-bit)
-V:3.12 Python 3.12 (64-bit)
-V:3.11 Python 3.11 (64-bit)Python 3.12系を指定して仮想環境を作成して、そこに入ります
py -3.12 -m venv whisper-env
.\whisper-env\Scripts\activatePyTorch、Whisperをインストールします
話者分離のpyannote、進捗表示のためのnumpyも入れておきます(任意)
python.exe -m pip install --upgrade pip
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
pip install openai-whisper
pip install pyannote.audio
pip install numpy scipy tqdmここで、PyTorchとGPUの認識を確認するスクリプトを作成して実行してみます
コメントの表示が出ればOKです
import torch
print(torch.__version__) # → 2.7.1+cu128
print(torch.cuda.is_available()) # → True:GPUが有効、False:CPUで動作Whisper Pythonで実装する自動文字起こしのサンプルコード
めちゃくちゃシンプルで最小限のサンプルコードを書いておきます
使い勝手など、実運用では色々機能を足したくなると思いますが
ひとまず動作することを確認できると思います
import whisper
print("Whisperモデルのロードを開始...")
# モデルをロード
model = whisper.load_model("large-v3")
print("Whisperモデルのロードが完了しました")
# 音声ファイルを指定
audio_path = r"C:\sample_audio.m4a"
# 文字起こしを実行
result = model.transcribe(audio_path, language="ja")
# 結果を表示
print(result["text"])whisper.load_model(“large-v3”)、の部分ですが
精度と速度のトレードオフで複数のオプションが用意されていまして
いくつか試したんですが、最高精度の”large-v3″でも、一部微妙になる部分があるので
時間をかけても最高精度の一択かな、と思ってます…
終わりに
こんな感じでフリーで、かつローカルで使用できる文字起こし環境が構築できました
音声文字起こしは、これまで手書きでがんばるか、有償ベースのサービスに頼るしかない…
という感じだったと思いますが、Whisperを使えば、
「高精度な自動文字起こしは有料でクラウド依存」という前提を覆すことができます
本記事の通り、Pythonで環境を構築すれば、個人でも高レベルの処理環境を構築可能です
但し、有償サービスはやはり有償なだけあって精度も高いので
使用目的や求める精度によっては、課金することで幸せになれると思います
PyTorchが大きな起因となって、Python、CUDAなどのバージョン制約があるところに関して
最初躓いてしまってものすごく時間を使ってしまったんですけれども
うまくいった結果を残せたと思うので、参考になればと思います
このあと、
複数ファイル処理の自動化や話者分離の導入、GUI機能の実装などもやってみて、実運用ができました
この辺りの拡張に関しては、また記事にして公開しようかなと考えています
大したコードでもないし、GitHubに上げることも検討中。。。


コメント